Un petit aperçu du fonctionnement de l'optimiseur
Par Arian Papillon le mercredi 16 juin 2021, 09:29 - Lien permanent
Le composant qui détermine le plus la performance d’un SGBDR est son optimiseur. Comme vous le savez sûrement déjà, le moteur de base de données adapte son plan d'exécution au contexte : il fait cela grâce à une estimation des cardinalités, ce qui lui permet de savoir approximativement quel nombre de ligne serait renvoyé pour chaque prédicat ou jointure de la requête.
Dans cet article, nous allons examiner son fonctionnement avec une requête simple.
Pour rappel, le traitement d’une requête dans le moteur relationnel passe par différentes phase avant l’exécution :
- l’analyse de syntaxe (le « parser »),
- l’algébrisation (l’ « algebrizer ») qui produit un arbre de requête standardisé : l’arbre de requête décrit les tâches à exécuter par la requête. Chaque nœud représente une opération, de jointure, de regroupement… Deux requêtes qui font la même chose tout en étant écrites différemment auront un arbre algébrisé identique !
- l’optimisation (l’ « optimizer ») qui va élaborer le plan d’exécution
C’est ce dernier composant (l’optimiseur) qui va décider des méthodes d’accès aux données (par exemple un parcours de table ou une recherche avec un des index ?) et du choix des différents algorithmes utilisés pour l’exécution, comme par exemple les jointures (loop, merge, hash join ?).
Ces choix sont très sensibles : on comprend aisément qu’un mauvais choix (une mauvaise optimisation) peut vite devenir catastrophique dès que le volume de données à traiter est conséquent !
Pour effectuer son travail, l’optimiseur s’appuie sur :
- l’arbre de requête « algébrisé » qui lui décrit les opérations à effectuer,
- les statistiques de distribution qui existent sur chaque index et sont générées en fonction des besoins (par défaut) sur des colonnes non indexées,
- les contraintes CHECK et FOREIGN KEY,
- des heuristiques
Je n’irai pas vous décrire le fonctionnement interne de l’optimiseur. Tout d’abord, c’est un secret bien gardé. Ensuite, il faut quelques solides connaissances mathématiques qui me font sûrement défaut. J’ai souvenir d’une présentation chez Microsoft à Redmond par une des conceptrices de l’optimiseur, toute timide mais gros cerveau de mathématicienne, qui nous a tous rapidement laissés pour compte à coups de formules mathématiques.
Nous allons juste examiner certains comportements simples et en particulier l’estimation des cardinalités, et voir comment une mauvaise estimation au départ peut s’amplifier au fil des jointures… !
Commençons par une requête simple qui joint les produits aux fournisseurs et filtre sur un nom de fournisseur.
select * from produits p
join fournisseurs f on p.IDFournisseur = f.IDFournisseur
where f.ContactNom = 'Carlos Diaz'
option (maxdop 1)
Voici le plan d’exécution réel (celui qui a été exécuté) :
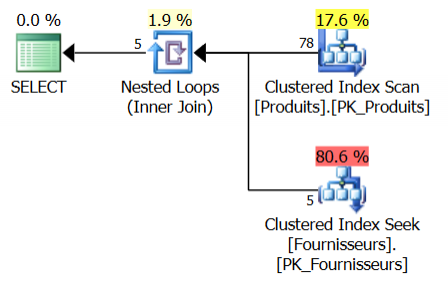
Les 78 lignes de la table produit ont été parcourues et une recherche d’index dans la table fournisseurs a été effectuée pour chaque produit. 5 produits correspondent.
Voyons maintenant le plan d’execution estimé (ce que SQL Server a estimé avec d’exécuter la requête) :
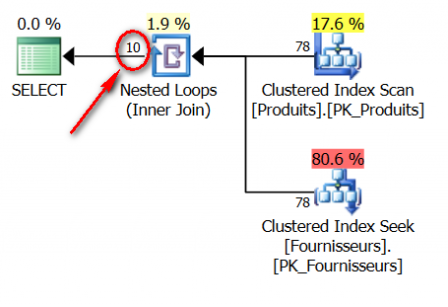
Nous constatons que SQL Server avait estimé le nombre de lignes correspondantes à 10 plutôt que 5. Une petite erreur du simple au double, qui en l’occurrence n’a aucun impact sur l’exécution d’une si petite requête.
Voyons maintenant de quoi a disposé l’optimiseur pour établir son plan de requête et la cause de cette erreur :
La table produits possède 78 lignes avec 30 fournisseurs différents. Cela donne donc en moyenne 2.6 produits par fournisseur. L’optimiseur est tenu au courant de ce fait grâces aux statistiques de la table produits sur la colonne IDFournisseur.
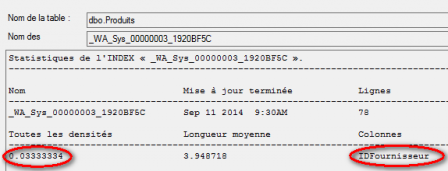
La densité affichée pour cette colonne est de 0.03333334, faisons le calcul.
Nombre moyen de valeurs uniques = nombres de lignes de la table x densité soit : 78 * 0.03333334 = 2.6
La table fournisseurs comprend 30 lignes. 4 lignes répondent à la condition « ContactNom = 'Carlos Diaz' ». SQL Server connait ce nombre grâce aux statistiques et à l'échantillonage présent dans la statistique : cette information est précise et suffisante. "Carlos Diaz" est fourni sous forme de constante (et non de variable), c'est pourquoi il peut utiliser les informations de l'échantillon (histogramme) dans les statistiques.
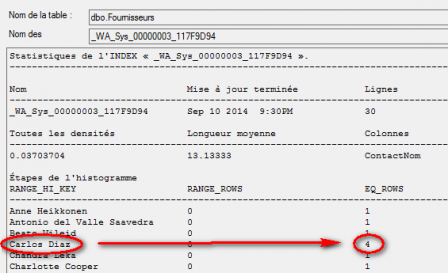
Pour estimer le nombre de correspondances de la jointure, SQL Server va utiliser la formule suivante :
((Nb total lignes produits * densité produits) * Nb lignes estimées fournisseurs) – (densité produits * Nb lignes estimées fournisseurs)
Soit ((78 * 0.03333334)*4)-(0.03333334*4) = 10.2666687 lignes estimées. CQFD...
On se doute qu'avec une telle imprécision (du simple au double), si ce résultat est lui même mis en jointure avec une autre table, puis encore, puis encore, ce qui augmente à chaque fois les cardinalités, l'écart entre l'estimation et la réalité pourra être énorme.
Ce problème existe dans les 2 sens : surestimation ou sousestimation. Il peut pousser l'optimiseur à choisir un plan d'exécution inefficace. Avec une surestimation, il peut par exemple estimer qu'il est plus pertinent de parcourir une table que d'y faire une recherche, il va allouer plus de mémoire que nécessaire, etc...
Vous devez donc surveiller ces écarts dans vos plans d'exécution. Pour l'aider à avoir les estimations les plus précises possibles, il existe plusieurs armes :
- maintenir à jour ses statistiques, si possible avec FULLSCAN
- ajouter des statistiques ou des index, multicolonnes et/ou filtrées
- écrire des prédicats "cherchables"
- simplifier les requêtes : les prédicats trop complexes augmentent fortement les erreurs d'estimation
- etc...
Mais tout cela, c'est le job d'optimisation des bases de données du DBA...