Les index filtrés
Par Arian Papillon le jeudi 2 mars 2023, 10:27 - Lien permanent
Depuis SQL Server 2008, il est possible de créer des index filtrés : des index nonclustered avec un prédicat WHERE, qui ne vont indexer qu'une partie de la table.
Bien que peu utilisés (je le constate souvent dans les bases que j'examine), l'utilisation des index filtrés peut nous aider à résoudre certaines problématiques de performances et peuvent réduire le volume de stockage.
Il faut cependant bien comprendre quelles sont les limites à leur utilisation : dans beaucoup de cas, les index filtrés que j'ai rencontré étaient mal utilisés !
Un index filtré est un index avec un prédicat de filtre : une cause WHERE ! Une partie des lignes seulement est donc indexée : l'index est "partiel", sa taille est réduite. Cela permettra d'améliorer les performances de certaines requêtes, consommera moins d'espace de stockage qu'un index "complet", et cette taille réduite permettra de limiter les coûts de maintenance.
Comment créer un index filtré
En ajoutant simplement une clause WHERE lors de la création de l'index, par exemple :
CREATE NONCLUSTERED INDEX ix$CommandesActives ON IDClient WHERE CommandeActive = 1
Seuls sont supportés les opérateurs de comparaison simples : =,<,<=,>,>=,<>.
Vous pouvez assembler plusieurs conditions avec AND, mais vous n'avez pas le droit au OR ou NOT, ni au LIKE ou aux fonctions dans le prédicat de filtre. Et vous ne pouvez pas non plus créer un index filtré sur une colonne calculée ou sur une vue indexée. Le filtre ne peut pas non plus être appliqué à une clé primaire ou une contrainte unique.
Chose importante : pour qu'un index filtré puisse être créé ou mis à jour, certaines options SET de la connexion doivent être correctement positionnées. C'est le cas par défaut dans SQL Server Management Studio, mais pas forcément dans votre application cliente : si les options requises ne sont pas toutes positionnées correctement, les mises à jour échoueront !
Échec de UPDATE car les options SET suivantes comportent des paramètres incorrects...
- Doivent être activés : ANSI_NULLS, ANSI_PADDING, ANSI_WARNINGS, ARITHABORT, CONCAT_NULL_YIELDS_NULL, QUOTED_IDENTIFIER.
- Doit être désactivé : NUMERIC_ROUNDABORT.
Index filtrés et performances
L'index filtré est utile pour les requêtes qui effectuent des sélection dans un sous-ensemble de données bien défini (celui du filtre de l'index), surtout si il y a besoin de parcourir l'index en entier (index scan) ou en partie : l'index étant beaucoup plus petit, le parcours nécessite moins de lectures et est donc plus rapide.
C'est surtout utile lorsqu'une colonne n'a que quelques valeurs pertinentes, inégalement distribuées. Par exemple, ma grosse table des commandes a une colonne CommandeActive : la plus grande partie des commandes de ma table sont déjà livrées et terminées (CommandeActive=0) et je n'ai qu'un faible sous-ensemble de commandes actuellement actives (CommandeActive=1).
Si j'indexe ma table des commandes avec un index filtré qui filtre sur WHERE CommandeActive = 1, certaines requêtes, celles qui ciblent uniquement des commandes actives (et qui le précisent bien dans le prédicat de recherche) pourront être améliorées. Non, pas toutes les requêtes, dans certains cas un autre index existant (ou un parcours de table) peut être plus efficace, et l'optimiseur choisit !
Autre avantage de l'index filtré : des statistiques filtrées seront de fait créées, améliorant l'estimation des cardinalités !
Les limites à l'utilisation d'un index filtré : attention !
Tout d'abord, pour qu'un index filtré puisse être choisi par l'optimiseur dans un plan d'exécution, il est indispensable que le prédicat de recherche correspondant au filtre soit exprimé dans la requête SELECT (ou UPDATE ou DELETE). Par exemple :
SELECT ID, ClientID, DateCommande FROM Commande WHERE CommandeActive = 1
Mais il faut savoir que le prédicat de recherche doit utiliser une constante, et surtout pas une variable. La requête suivante sera incapable d'utiliser l'index filtré :
SELECT ID, ClientID, DateCommande FROM Commande WHERE CommandeActive = @VarActive
Dans ce cas on pourra trouver un avertissement dans le plan d'exécution : "Unmatched Index" (à regarder dans les propriétés du plan d'exécution). Cela signifie qu'un index existe bien, mais il ne peut pas être utilisé pour résourdre la requête. En effet, lorsqu'on utilise une variable dans un prédicat de recherche, l'optimiseur ne connait pas la valeur au moment de la compilation du plan.
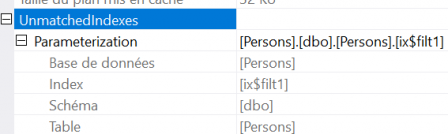
Il est donc parfois nécessaire de "doubler" l'index filtré par sa version non filtrée pour parer à différents cas de figure !
Et les NULLS ?
L'index filtré peut aussi nous permettre de contourner une problématique absurde propre à SQL Server : lorsqu'on crée un index unique sur une colonne, SQL Server traite le NULL comme une valeur et ne nous permet d'en insérer qu'un seul !
L'index filtré peut nous permettre de parer à cela, comme dans l'exemple suivant :
CREATE UNIQUE INDEX ux$UniqueNameAllowNulls ON dbo.Persons (UniqueName) WHERE UniqueName IS NOT NULL