Une question que posent souvent les développeurs : comment éviter les verrous bloquants à la lecture des données ?
Une des (mauvaises) solutions est d'utiliser la directive NOLOCK (ou isolation READ UNCOMMITTED) : c'est un faux ami car cela ne garantit pas la cohérence transactionnelle des données que l'on lit.
L'autre solution est d'utiliser un niveau d'isolation "optimiste", par versionning : SNAPSHOT ou READ COMMITTED SNAPSHOT (RCSI).
Le principe de l'isolation par versionning est le suivant : plutôt que de poser un verrou partagé pour lire les données (ce qui empêchera de lire des données en cours de modification), SQL Server va renvoyer la dernière version validée des données : il utilise pour cela le "Version Store", qui stocke de manière transparente cette version des données dans Tempdb.
Un effet de bord mal connu de l'isolation SNAPSHOT (ou RCSI) est qu'il ajoute un pointeur de 14 octets à chaque ligne de données dès qu'on la modifie, ce qui peut poser certains problèmes. Voyons cela de plus près.
 Une question qui m'a été posée : comment savoir si la colonne d'une table contient des caractères accentués ou des minuscules et comment y éliminer les accents ? Cela avec SQL comme avec SSIS : voyons quelques astuces...
Une question qui m'a été posée : comment savoir si la colonne d'une table contient des caractères accentués ou des minuscules et comment y éliminer les accents ? Cela avec SQL comme avec SSIS : voyons quelques astuces... Le Power Saturday / SQL Saturday 2020 à Paris se tiendra le 6 juin 2020. Ce sera une manifestation en ligne, covid-19 oblige.
Le Power Saturday / SQL Saturday 2020 à Paris se tiendra le 6 juin 2020. Ce sera une manifestation en ligne, covid-19 oblige. Non, ce n'est pas la pub pour le dernier smartphone et ça ne date pas d'aujourd'hui : c'était la présentation du premier ordinateur personnel d'IBM, l'IBM PC de 1981.
Non, ce n'est pas la pub pour le dernier smartphone et ça ne date pas d'aujourd'hui : c'était la présentation du premier ordinateur personnel d'IBM, l'IBM PC de 1981.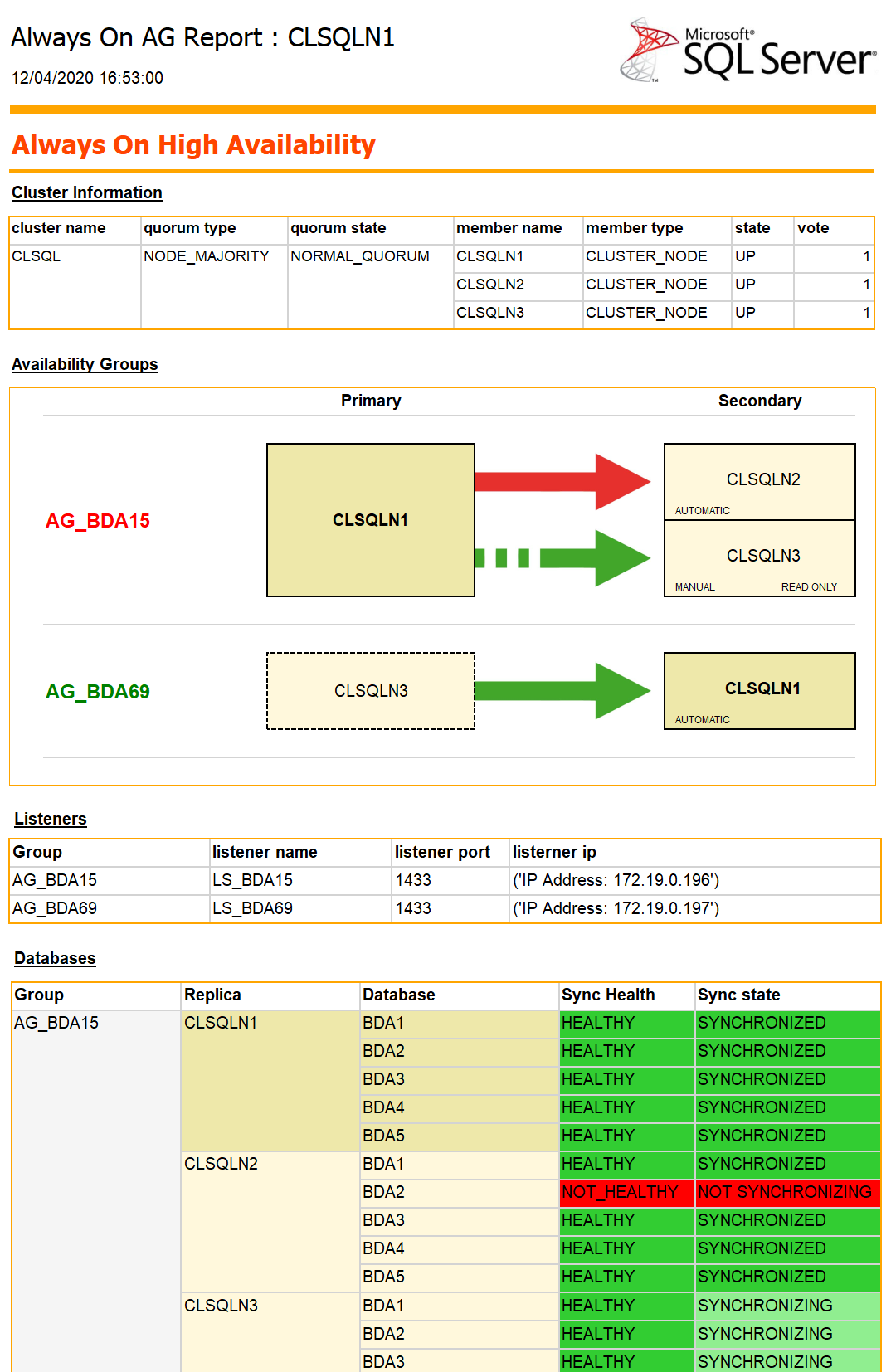
 Une
Une 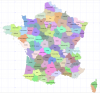 Par ces longues soirées (de confinement), c'est le moment de réviser sa géographie avec des requêtes SQL... Cette base de données recense les 36000 communes françaises, les départements et les régions. Je l'ai mise à jour à partir des données (publiques) de la poste et j'y ai ajouté les départements et les régions.
Par ces longues soirées (de confinement), c'est le moment de réviser sa géographie avec des requêtes SQL... Cette base de données recense les 36000 communes françaises, les départements et les régions. Je l'ai mise à jour à partir des données (publiques) de la poste et j'y ai ajouté les départements et les régions.