 Une nouvelle vidéo sur la chaîne youtube Datafly : c'est un petit retour d'expérience sur le déploiement de mon cluster big data SQL Server 2019. S'appuyant sur Linux (ubuntu) et Kubernetes, on parcourt les principales étapes du déploiement de ma plate-forme de test et quelques commandes de troubleshooting. Pour plus d'informations sur l'architecture des clusters big data de SQL Server 2019, vous pouvez regarder une vidéo précédente de cette même chaîne : https://youtu.be/XvEc7OUbyCs
Une nouvelle vidéo sur la chaîne youtube Datafly : c'est un petit retour d'expérience sur le déploiement de mon cluster big data SQL Server 2019. S'appuyant sur Linux (ubuntu) et Kubernetes, on parcourt les principales étapes du déploiement de ma plate-forme de test et quelques commandes de troubleshooting. Pour plus d'informations sur l'architecture des clusters big data de SQL Server 2019, vous pouvez regarder une vidéo précédente de cette même chaîne : https://youtu.be/XvEc7OUbyCs
L'installation d'une plate-forme de ce type n'est pas une mince affaire, surtout on premise : importantes ressources matérielles (4 VM largement dotées en mémoire (56 Go), en CPU (8 cores) et en disque (200 Go)), installation de linux, installation de l'orchestrateur Kubernetes, personnalisation puis déploiement du cluster SQL Server 2019.
Et du temps : d'abord pour tout installer et configurer, avec les problèmes inhérents aux configurations sous linux, il faut quelques jours. Puis pour déployer : avec les dizaines de Go d'images à télécharger et ma bande passante "campagnarde", le déploiement prend quinzaine d'heures. Tout cela avec deux gros quadri-processeurs qui font office de chauffage électrique (en plus bruyant) dans le bureau.
Retour vers le futur aussi : se remettre à la ligne de commande, comme dans les années 80 (vieux souvenirs) !
 Question très souvent posée : comment peut on changer le classement (collation) d’une base de données ? Passer par exemple de case sensitive à case insensitive ? Vous verrez ici que l'opération est loin d'être simple !
Question très souvent posée : comment peut on changer le classement (collation) d’une base de données ? Passer par exemple de case sensitive à case insensitive ? Vous verrez ici que l'opération est loin d'être simple !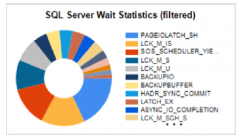 Cet article décrit ce que sont les "wait statistics", comment ces informations peuvent vous aider à diagnostiquer des problèmes de performances, et pourquoi vous trouvez certaines requêtes avec un statut "SUSPENDED".
Cet article décrit ce que sont les "wait statistics", comment ces informations peuvent vous aider à diagnostiquer des problèmes de performances, et pourquoi vous trouvez certaines requêtes avec un statut "SUSPENDED".
 Une nouvelle version de mes "Custom Information Reports for SSMS", version 6.5.2 a été publiée. Ces rapports vous permettent d'obtenir rapidement une vue complète de votre instance SQL Server et de ses bases de données. C'est mon outil de travail de tous les jours et nombre de mes clients l'utilisent. Les 11 rapports vous permettent d'examiner la configuration du serveur, la configuration et la santé des bases de données, les travaux de l'agent SQL Server, les informations de performance, les tables, index, statistiques, etc...
Une nouvelle version de mes "Custom Information Reports for SSMS", version 6.5.2 a été publiée. Ces rapports vous permettent d'obtenir rapidement une vue complète de votre instance SQL Server et de ses bases de données. C'est mon outil de travail de tous les jours et nombre de mes clients l'utilisent. Les 11 rapports vous permettent d'examiner la configuration du serveur, la configuration et la santé des bases de données, les travaux de l'agent SQL Server, les informations de performance, les tables, index, statistiques, etc... Il est fréquent d'avoir à importer des données d'un tableau Excel dans une table. Nous verrons ici qu'il existe plusieurs moyens simples de le faire, mais qu'un peu de recherche et de configuration préalable (pour ne pas dire "bidouille") sont nécessaires.
Il est fréquent d'avoir à importer des données d'un tableau Excel dans une table. Nous verrons ici qu'il existe plusieurs moyens simples de le faire, mais qu'un peu de recherche et de configuration préalable (pour ne pas dire "bidouille") sont nécessaires. Le "batch mode on row store" : encore une nouveauté de l'optimiseur de SQL Server 2019 qui améliore sensiblement les performances de certaines requêtes. Cette vidéo disponible sur la chaine youtube Datafly vous en fait la démonstration et vous allez voir que cela peut être diablement efficace.
Le "batch mode on row store" : encore une nouveauté de l'optimiseur de SQL Server 2019 qui améliore sensiblement les performances de certaines requêtes. Cette vidéo disponible sur la chaine youtube Datafly vous en fait la démonstration et vous allez voir que cela peut être diablement efficace. Savez-vous que SQL Server capture en permanence les évènements deadlocks qui surviennent, grâce à sa session d'évènements étendus toujours active ? Découvrez comment exploiter ce journal et afficher les derniers deadlocks en format graphique...
Savez-vous que SQL Server capture en permanence les évènements deadlocks qui surviennent, grâce à sa session d'évènements étendus toujours active ? Découvrez comment exploiter ce journal et afficher les derniers deadlocks en format graphique...