Par Arian Papillon le vendredi 28 octobre 2022, 18:01
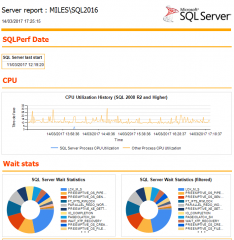 Une nouvelle version de mes rapports custom pour SQL Server Management Studio, la v8 !
Une nouvelle version de mes rapports custom pour SQL Server Management Studio, la v8 !
Beaucoup d'améliorations un peu partout dans cette release, et en prime deux rapports supplémentaires sur la sécurité au niveau instance et base, ce qui porte le nombre de rapports à 15.
Pour ceux qui ne les connaîtraient pas déjà, cet ensemble de rapports chaînés vous permettent d'avoir un aperçu rapide et graphique d'une instance et de ses bases de données, sous tous ses aspects : configurations, erreurs, stockage, backups, jobs, sécurité, performances... Et tout cela sans devoir passer par des dizaines de requêtes ou boîtes de dialogue. Un sacré gain de temps !
Côté pratique, ils se lancent directement dans SSMS et peuvent être exportés (pdf) ou imprimés... je m'en sers tous les jours ! (pour l'anecdote, j'ai appris que des consultants Microsoft les utilisent ou les déploient chez leur clients...)
Vous pouvez les télécharger sur https://github.com/datafly/ssmsinforeports

 Une problématique je trouve de plus en plus souvent chez de nombreux clients :
Une problématique je trouve de plus en plus souvent chez de nombreux clients :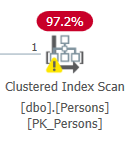 Les problèmes de conversion de types de données sont un des problèmes de performances trop souvent rencontré.
Les problèmes de conversion de types de données sont un des problèmes de performances trop souvent rencontré.
 N'oubliez pas de maintenir vos versions de SQL Server à jour avec les derniers correctifs de sécurité !
N'oubliez pas de maintenir vos versions de SQL Server à jour avec les derniers correctifs de sécurité ! La sécurité des données est une préoccupation de plus en plus fréquente depuis la législation pour la protection des données personnelles (RGPD) et à cause de l'actualité qui montre que les fuites de données sont de plus en plus fréquentes.
La sécurité des données est une préoccupation de plus en plus fréquente depuis la législation pour la protection des données personnelles (RGPD) et à cause de l'actualité qui montre que les fuites de données sont de plus en plus fréquentes.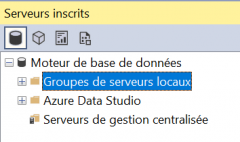 Dans SQL Server Management Studio, la liste des serveurs inscrits est une fonctionnalité bien pratique. Ma propre liste comprend près de 300 serveurs : les miens et ceux de mes clients. Maintenant que le travail à distance est une réalité quotidienne, j'ai besoin de transférer tout cela de mon ordinateur portable à mon ordinateur de bureau.
Dans SQL Server Management Studio, la liste des serveurs inscrits est une fonctionnalité bien pratique. Ma propre liste comprend près de 300 serveurs : les miens et ceux de mes clients. Maintenant que le travail à distance est une réalité quotidienne, j'ai besoin de transférer tout cela de mon ordinateur portable à mon ordinateur de bureau.