Pour cette session des Datafrogs, le 1er juin, le sujet de notre présentation était "Ménage de printemps".
Il y a sûrement plein de choses qui ne servent plus à rien dans vos instances SQL Server, ce qui crée des trous de sécurité et augmente inutilement la consommation de ressources :
- Combien de login avez vous qui ne servent plus à rien ?

- Combien d'utilisateurs SQL sont orphelins dans mes bases ?
- Combien de bases ne sont plus accédées ?
- Combien de fichiers de données ou de groupes de fichiers sont vides ?
- Combien de table ne sont plus accédés ?
- Combien d'index ne sont plus utilisés ?
- Combien d'index sont redondants ou inclus ?
- Combien de statistiques sont redondantes ?
Vous verrez que ce n'est pas si simple que cela à trouver et nettoyer.
Les diapositives sont ici, et les scripts (une partie) là. La vidéo suivra.
Bon ménage...
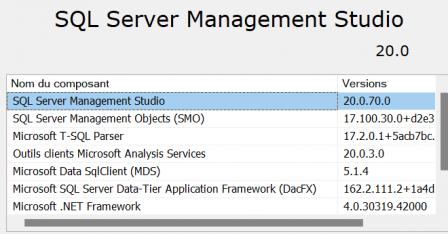 Le nouveau SSMS (SQL Server Management Studio) version 20 est arrivé.
Le nouveau SSMS (SQL Server Management Studio) version 20 est arrivé. Encore une nouvelle version de mes rapports custom pour SQL Server Management Studio, la 9.2 !
Encore une nouvelle version de mes rapports custom pour SQL Server Management Studio, la 9.2 ! Hélas, on a laissé jouer les développeurs sur la base de production !
Hélas, on a laissé jouer les développeurs sur la base de production !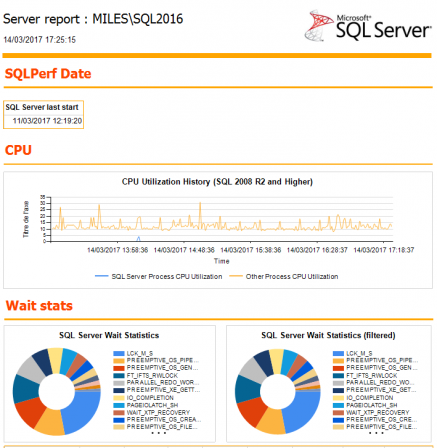 Une nouvelle release de mes rapports custom pour SQL Server Management Studio, la v9 !
Une nouvelle release de mes rapports custom pour SQL Server Management Studio, la v9 ! Samedi 14 octobre à 14h45, j'aurai le plaisir de présenter une sessions sur les "Query Hints" ou "Indicateurs de requête".
Samedi 14 octobre à 14h45, j'aurai le plaisir de présenter une sessions sur les "Query Hints" ou "Indicateurs de requête". Etape importante de configuration post-installation, à minima retoucher les paramètres de l'instance :
Etape importante de configuration post-installation, à minima retoucher les paramètres de l'instance :